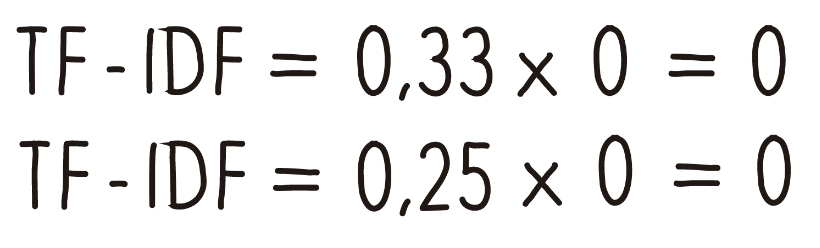No doubt one of the three main factors influencing SEO positioning is the content and how it is generated following different optimization parameters.
Now, to know how relevant the content of a site is to the query made by the user, the term TF-IDF (term frequency-inverse document frequency) arises, a first cousin of what was known until some time ago in the old school of SEO as keyword density.
The use of this last concept started to decrease due to opposing positions on the idea that the more times a keyword is repeated on a page, the greater its relevance.
In this context, and within the machine learning framework, TF-IDF arises. It determines a numeric value that defines the importance of a particular keyword within an entire site. Knowing this is important because if, for instance, we have a coffee shop site and the keyword “coffee” has a low TF-IDF, the term is not being optimized correctly for SEO.
To better understand the concept, let’s take an example. A website is composed of two pages:
-el café espresso (page 1)
-el café espresso americano (page 2)

The first step is to analyze how many times each word is repeated in the content of the pages I am analyzing:
We see then that all words are repeated 2 times, except for the keyword “americano”. This leads us to interpret that the first three words are the ones with the highest term frequency (TF), while “americano” is the one with the lowest repetition within the site, corresponding to the inverse document frequency (IDF).
It is impossible to determine exactly the right percentage for content to rank for a specific search.
On the other hand, we must not forget that texts must always be written with the user in mind, and not taking the search engine as the main objective, so repeating relevant terms will be favorable, as long as we mention them in necessary contexts, without abusing their use, as this may be counterproductive.
How to determine the frequency of the term
If you are interested in knowing a little more in-depth about how the value we mentioned before is determined, then continue reading this section :)

Let’s take the example we saw before. To know the term frequency (TF) we must do the following calculation for each word inside each document:
Now let’s replace it with one of the words: the term frequency of the word “the” within document 1 is equal to how many times the term is repeated, over the total number of words in document 1.
This determines that the TF for the word “the” within document 1 is 0.33.
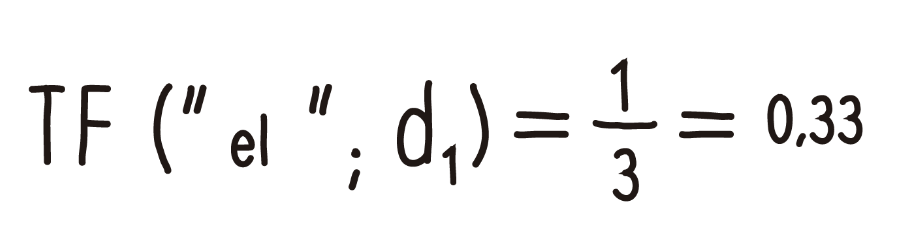
The next step is to do the same for the word “the” within document 2. If we replace it in the formula we would be left with something like this, and the value of TF, in this case, would be 0.25.

Now we have to calculate the value of the inverse document frequency (IDF), what we have to do is to replace the data we have, in the following formula:
This means that IDF is equal to the logarithm of the total number of documents divided by the sum of all the times a term is repeated in the document.
If we pass it to the example we have already seen, the value of IDF would be 0 (zero) and we would be left with something like this:
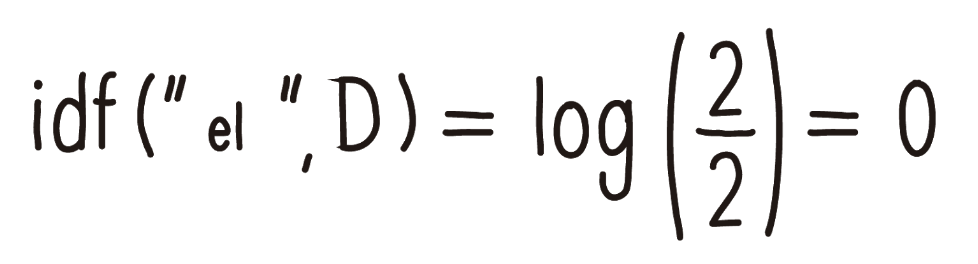
To conclude and determine our TF-IDF value we must know that:
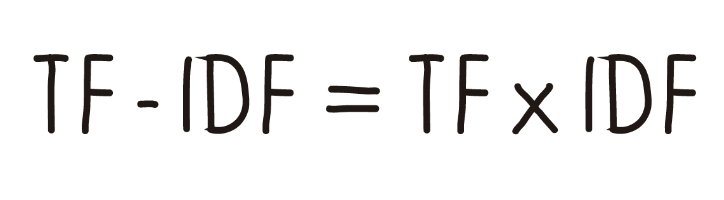
Therefore, we replace with the values we calculated for the word “the” within documents 1 and document 2, and we would arrive at the TF-IDF for both being zero.