
For those who don’t know it yet, Screaming Frog is one of the most useful tools to audit a site for SEO. It consists of an application that crawls a site by entering the initial URL and then each of its links until it has read the entire site. The result is a lot of valuable information about the site, be it URLs, pages with errors, redirects, titles, metadata, etc.
Like any tool, some people only use it for basic purposes without knowing that there is a lot of juice that can be extracted from it. In today’s post, we are going to show you how you can analyze the internal linking strategy of your competitors. As a consequence, you will be able to take the insights extracted from crawling to optimize your internal linking strategy accordingly.
To achieve this, we are going to extract anchor texts from the internal links of a site. It should be noted that there are easier ways to do this with Screaming Frog… however, today we are going to show you a slightly more advanced method that can also be used to read all the HTML tags that exist on a page.
Our goal is to collect data from the source code of one or more pages. This practice is also known as web scraping. Remember to stay within the terms and conditions of the site whenever you are reading its source code using an application.
Let’s get started! Inside Screaming Frog, let’s go to the menu Configuration > Custom > Extraction. This section allows you to extract data from the source code of the pages you crawl. If you are using a free version of SF, this option will be disabled. We recommend investing in a full version if you regularly do SEO audits.
Anchor text benchmarking
Benchmarking is a practice based on analyzing how your competition behaves to adjust your strategy according to what you have learned. In today’s case, we are going to study the anchor texts of internal links. To do this, you will need to configure the following regular expression (regex, for friends) in the menu custom > extraction:
<a.*?>(.*?)<\/a>
This snippet captures everything inside <a> tags and reads as follows:

It captures all characters inside each <a> tag regardless of the Html attributes of the tag and stops capturing when the tag is closed. If you are not yet very familiar with Regex, we recommend you do some research online.
Regex is not the only way to extract information from text. There are other methods such as XPath that work a bit more with the DOM (Document Object Model) of the page. Below we detail the snippet to lift all the <a> tags with XPath.
//a
Make sure that the option “XPath” and “Extract Text” are selected so it extracts only the text and nothing else since some links are associated with image tags.

Whether we use a Regular Expression or the XPath, once it is configured we run the crawler so that it starts lifting each anchor text of each link within each page that is read.
Once the crawl has been run, to see the results we only have to look at the “Custom” tab and then choose “Extraction” from the dropdown.
Once the crawl has been run, to see the results we only have to look at the “Custom” tab and then choose “Extraction” from the dropdown.

Note that in addition to the ”extraction” item there are several additional filters. If more than one filter is configured, each of them will appear in its dropdown item. Since we only use the extraction menu, we select the last item in the list.
And that’s it! We can see that Screaming lifted all the anchor tags of the links. This data can be exported to CSV by clicking on the ‘Export’ button.

Another method similar to this is to analyze the links in the links instead of the anchor texts. To accomplish this we just need to run the following Regex custom extraction filter in Screaming Frog:
href=”(.*?)”
These are just a couple of examples of scrapings that can be performed. You may have to scrape other elements such as h3 header tags, spans, hidden divs, custom HTML tags, etc.
How to graph the results
We already have the data, now let’s see what insights are born from it. If we pass the CSV we exported to a spreadsheet and clean it up a bit we can put together a graph with the number of anchors that are most repeated.
Graph of the most repeated anchor text in our crawl
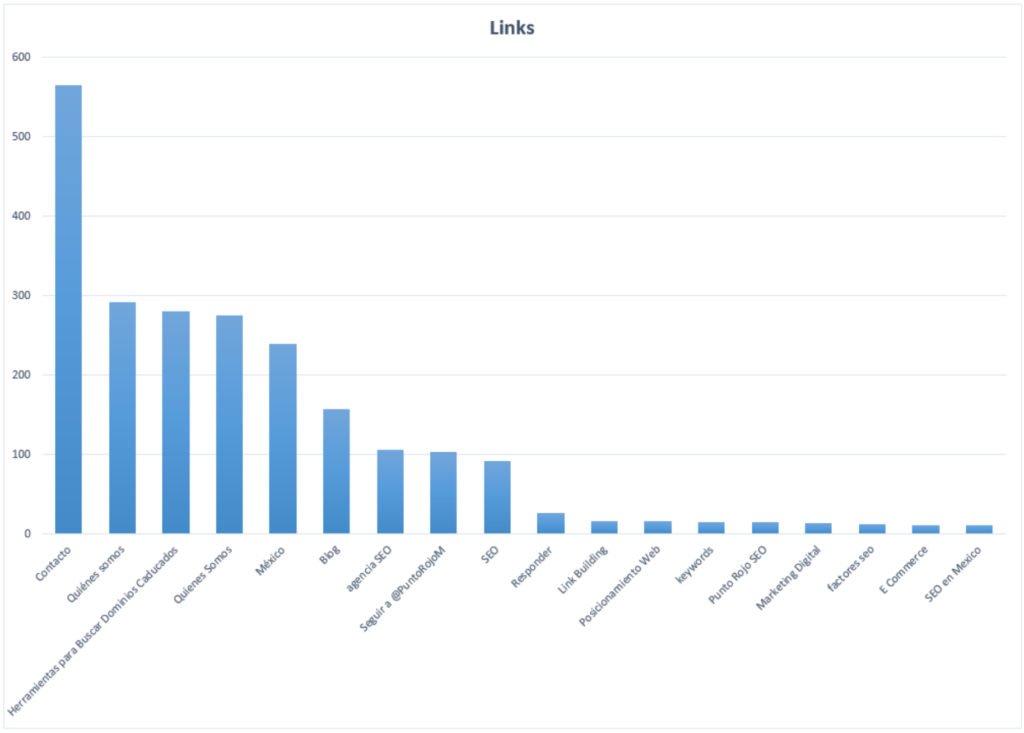
To build a chart similar to this one, just follow the steps below:
- Within a spreadsheet, list in a single column all the keywords that were collected. Several values will likely appear more than once as there may be more than one link with the same anchor text.
- Copy the column and paste it into the column next to it.
- Select the column and remove duplicates. If you are using Microsoft Excel, you can go to the Data menu > Remove duplicates.

If you are using Google Sheets, you will probably need to download a plugin to remove duplicate values. There are ways to remove duplicates in Google Sheets without using a plugin, but it falls outside the scope of this post.
- At this point we have all the terms in one column and then all the terms without duplicates in the next column.
- With a simple COUNTIF* function we can find how many times a single term is repeated in the list of all terms.
- Final step, we plot the data to obtain a graph similar to the one above.
*The formula syntax is =COUNTIF(range_with_duplicates; keyword_to_search)
Conclusion
If we dig a little, we can find advanced functionalities within Screaming Frog that allow us to know in-depth what our competitors link the most. In addition to this, we can obtain a great amount of information from both our competitors’ sites and our sites.
What are the advanced features of Screaming Frog that you use the most? Let us know by leaving a comment below and, as always, good rankings!


