
One of the concepts that you surely may have heard when talking about SEO is “Indexing”.
Indexing is one of the most important elements that we should take care of for our site, that is because a web that is not indexed is not visible in the Google search results or any other search engine.
In the same way, if you have indexed content that shouldn’t be shown in Google, this may probably affect your ranking.
Let’s see a more specific definition of indexing, followed by some advice on how to optimize it. Will you join me?
What is Indexing?
To be able to define indexing, first, we have to know what is the process that Googlebot (based on the fact that Google is the most widely used search engine) uses to make a URL visible in its search results:
- Crawling: Google uses “spiders” to navigate the different sites. The path can be forced or not. It’s forced when we do some action to get this crawling done (we will see this later), while in some sites it enters regularly.
- Indexing: once this navigation is done, Google decides if it shows content in its search results or not. In case it does, your URL or web will be “indexed”. The speed at which content is indexed can be a determining factor, especially on news websites.
- Publication: Google classifies this content and assigns you a position in its ranking for the different queries.
With all this in mind, we define indexing as the process in which search engines find, analyze your content, store it in their database and then give it visibility in search results.
Difference between indexing and crawling
Google indexes what it considers relevant, that’s why a crawled page it’s not necessarily an indexed page.
In the same way, we can make Google crawl some of our URLs and indicate that they are not indexable.
We will see this later, but meanwhile, think which of your site pages shouldn’t be showing in the search engine and which should.
A practical case is the legal notices and privacy policy pages. Should they be indexed? No, not at all. If you copied and pasted a privacy policy on your website from a third party and that URL is indexed you are incurring duplicate content.
How to see what is your indexing status?
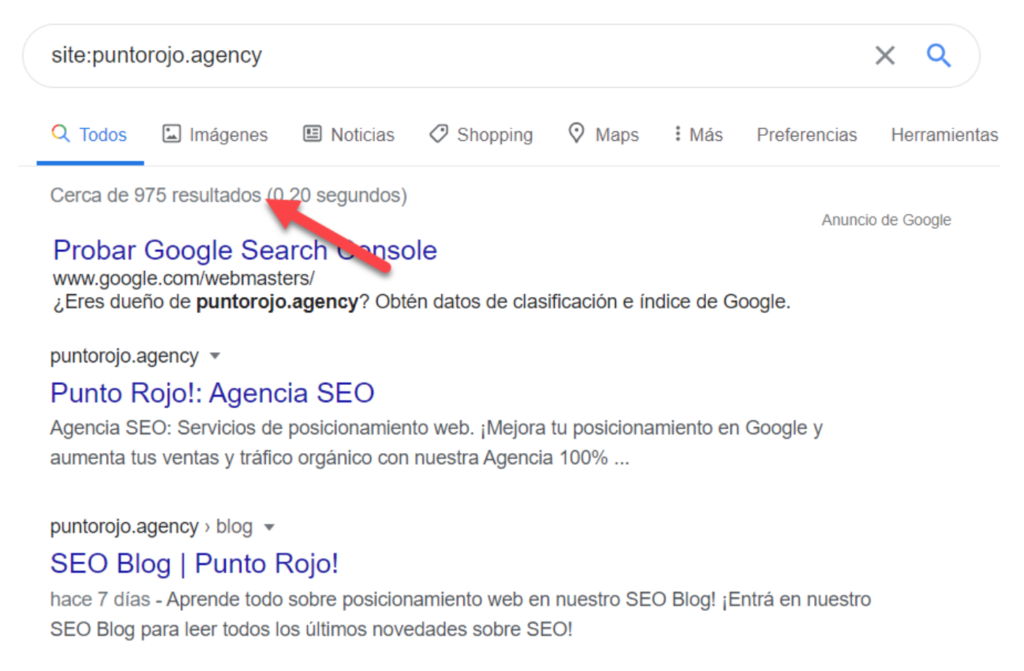
1. Command “site:” in Google
If you want to know how many of your site URLs are appearing in Google you can just use the command site:yourdomain.com on the search bar.
As a result, you will get the total indexed URLs, as you can see in the following example:
2. Google Search Console Tools
Knowing the status of indexed pages from Google Search Console it’s very simple. To see it, go to the left sidebar > Coverage > “Valid”.
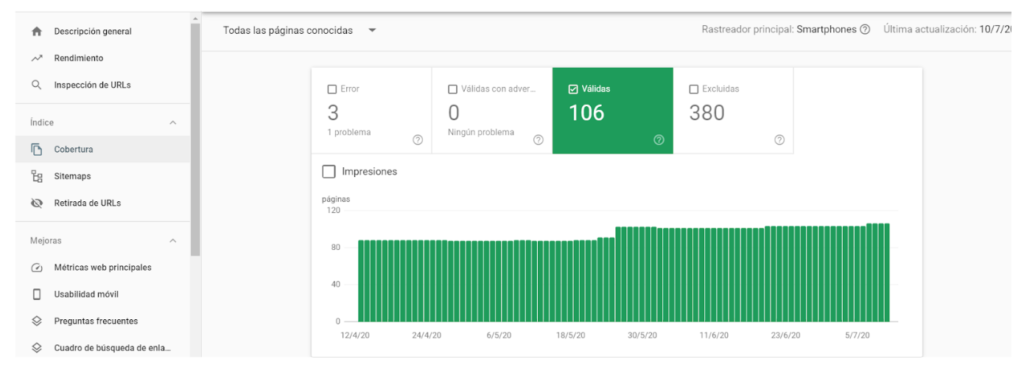
Search Console itself will also show you which URLs are not being displayed due to an error or if it is valid but with warnings.
Usually, this happens when for some reason your URL was crawled, Google tries to index it but some problem prevents it. Some of the most common problems are errors 4xx, 5xx or that the URL is included in the Sitemap but is not indexable, as we can see below:
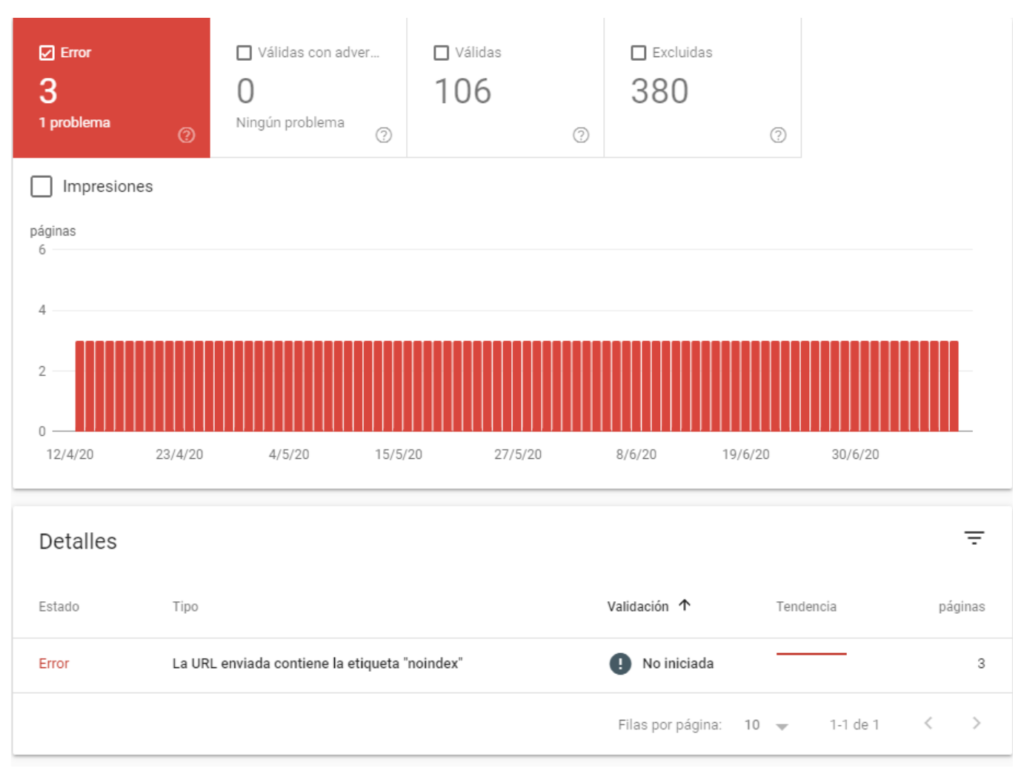
You will see the total number of URLs with issues and, if you click on them, it will list them. You can export this list and then work on Excel or Spreadsheets.
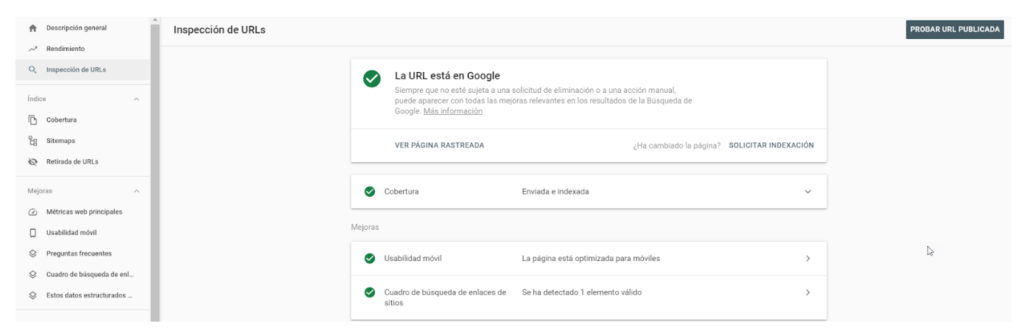
You can also use the “URL Inspection” tool to verify a specific page:
3. Seerobots Extension
Important: more than knowing if the page is indexed, this tool shows you if it can be indexed or if there is a guideline that prevents it.
An easy way to know if a URL is being indexed or not, including your competitor’s websites or those you don’t have access to in Search Console, is by using the Seerobots Extension.
The disadvantage is that it is not available for Chrome, but you can still use it in Mozilla Firefox: https://addons.mozilla.org/en-US/firefox/addon/seerobots/
To use it you have to enter the URL you want to analyze and click on the extension. It will show you if it is crawlable and indexable:

4. Screaming Frog
Very similar to the previous point, with Screaming Frog we will know which URLs may be indexable or not, but not know if they are indexed.
To do this open Screaming Frog > Add the URL of your website > Start crawling.
Once finished you will see that in the columns will be the following “Indexability” and “Indexability Status”:

Remember that you can also export this list and then work on Spreadsheets or Excel.
How to improve your indexing?
Use of Google Search Console for manual indexing
If you have just published a page and you want it to be displayed instantly in the search engine, you can use the Google Search Console tool to achieve it.
To complete it you just have to go to URL Inspection > Insert your URL
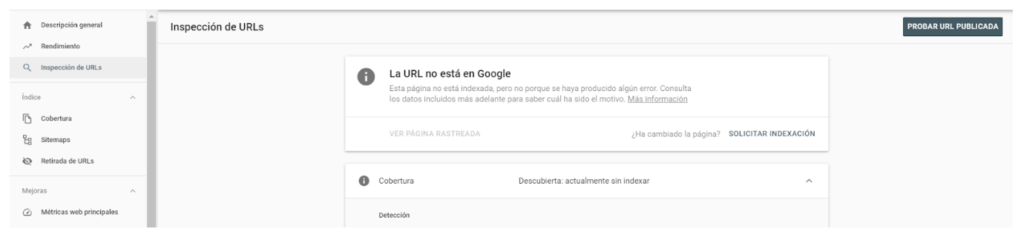
You will get the message “The URL is not in Google”. In the bottom right corner, you will have the option to request indexing manually, click there, and wait for the next message:
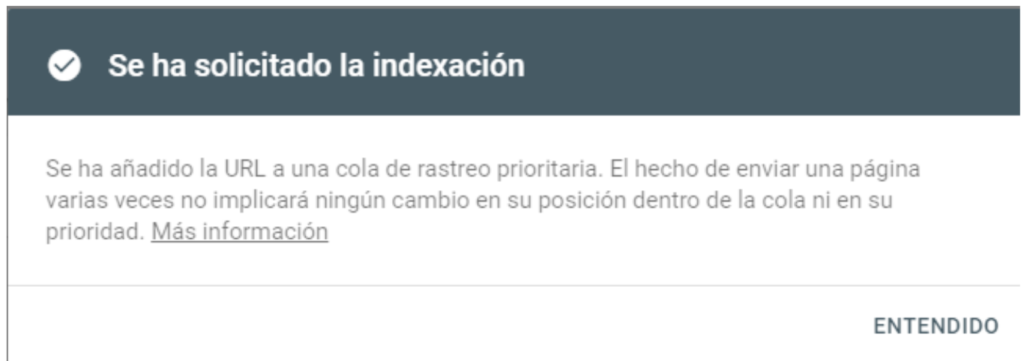
With this, you will have completed the manual indexing. From the rest, you just have to wait a few minutes to check with the “site:” command if the URL appears in Google or not.
Sitemaps.xml
Sitemaps are a file in .xml format that makes it easier for Googlebot to read and crawl the contents of your site. Before implementing it, make sure that all the URLs included in your sitemap have code 200 status.
Although there are different methods to create and implement it, among the most used are the following:
Sitemap with Screaming Frog
This powerful tool can also help you generate your sitemap easily. To do this you must Crawl your site > Sitemaps > XML Sitemaps > Next and it will automatically download a .xml file that you must then upload to your domain’s FTP.
If you want to know more details, check this article.
Sitemap para WordPress
If you use WordPress you can install a plugin that automates the creation of sitemaps on your site. There are some generalists in terms of SEO, such as Rank Math or Yoast, but you can also use one like “Google Sitemaps XML” which is the one I usually use.
To download it click here.
Manual sitemap generation
You can also build your sitemap manually, although this is the longest and most tedious way.
To complete it, follow the instructions provided by Google for its generation and implementation: https://support.google.com/webmasters/answer/183668?hl=es
Dynamic Sitemaps
Dynamic sitemaps are often used on sites where the content published is constantly changing and Google must index your content accordingly. This is especially true for news portals.
To build it you can do it using PHP, Javascript, or Python. If you do not know about these languages we recommend that you ask a web programmer.
Interlinking
Google crawls content through links (internal or external). In case you publish a new page and it does not receive links, your URL will be “orphaned”, and those orphaned URLs are more complicated to index.
Therefore, a good recommendation is that once you publish new content, it should contain inbound links from others on the same site.
A plus would be to link that URL from the most visited pages or with more backlinks.
Although these are the most important, you can also boost indexing through tools with API Indexing (limited at the moment) or through Backlinks.
How to block and control the indexing of my content?
Controlling the way your site is indexing is an excellent way to improve your site’s health and therefore boost your Google ranking.
For this there are different tools and guidelines that we can use to make a URL, category, file type or even an entire website disappear from search results:
Robots.txt
The Robots.txt file tells the crawlers (not only Googlebot) which sections of the site it can and cannot go to.
If you want to know more about how this file is put together, see Google’s official instructions: https://support.google.com/webmasters/answer/6062596?hl=es
To prevent Google Bot from crawling any section of your website just apply the “Disallow” directive.
Let’s imagine that you want to prevent it from crawling the privacy policy, in that case, the directive to include would be the following:
User-agent: *
Allow: /
Disallow: /politica-de-privacidad/
Google takes all these guidelines into account as recommendations, and they are generally followed. However, there is a possibility that despite the blocking from robots.txt Googlebot decides to crawl anyway.
Another case in which crawling occurs despite blocking from Robots.txt is when a blocked URL receives internal links from other crawlable and indexable pages.
Noindex label inside the meta robots
Just as there are semantic tags such as <h1> or <h2> to contextualize your content, there is also a tag called “meta robots” that tells crawlers whether or not to crawl and index a page.

The following attributes can be added to this tag:
- Index: the URL can be indexed in the search engine.
- Noindex: the URL cannot be indexed in the search engine.
- Follow: the URL can be crawled.
- Nofollow: the URL cannot be crawled.
If you want your content to be deindexed your meta robots will look like this:
<meta name=“robots” content=”noindex”>
This code snippet must be included between <head> tags of the URL you want to modify.
The only thing to keep in mind: be careful not to apply it to the whole site!
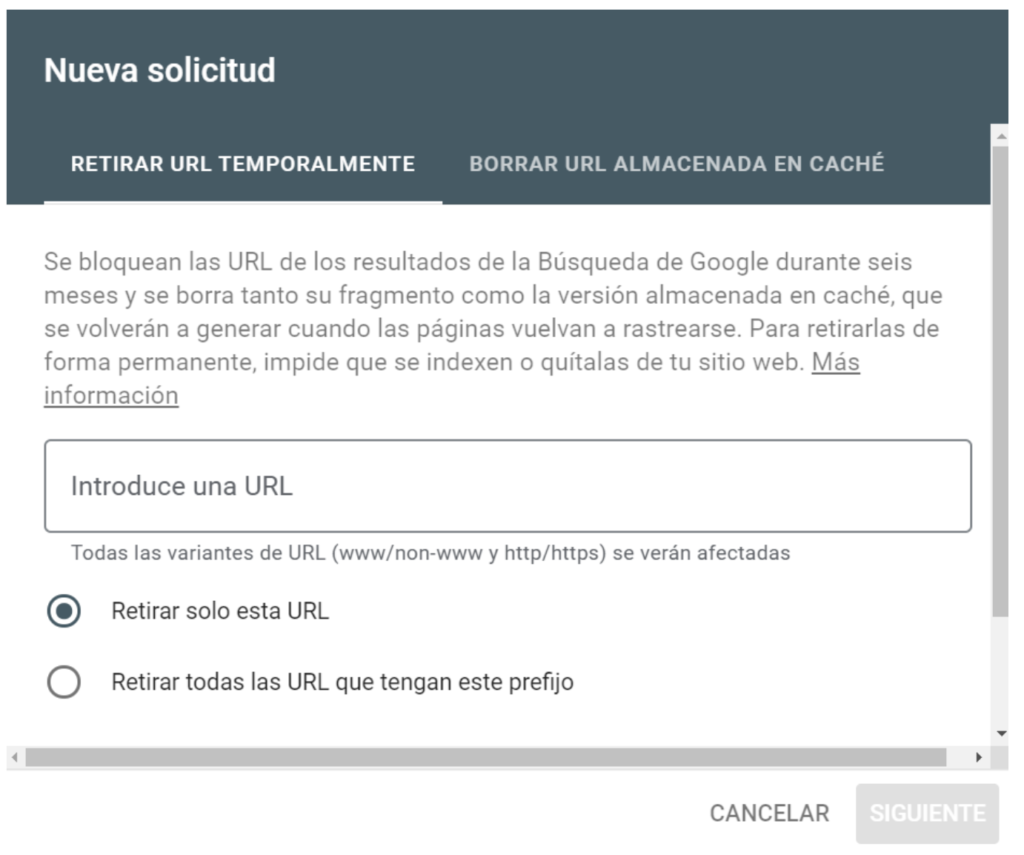
URL removal tool
Search Console once again allows us to take control and deindex content in a very practical and fast way. It also allows us to do it in bulk mode to remove hundreds of pages at the same time (in case you have a lot of URLs on your website).
To do this go to the left sidebar > Remove URLs > New request > Enter the URL you want to index and click “Next”.
In case you want to remove an entire directory, you can set the option “Remove all URLs containing this prefix”, so you can remove a whole segment of your website in one click.
Final Recommendations
Keeping track of your coverage in Google Search Console, looking at how many URLs are indexed in Google, and determining which pages you want to appear or not will be fundamental to controlling your indexing.
In the case of media (News portals), optimizing sitemaps to improve the content indexation is vital. In that case, you should implement an optimized sitemap for Google News, and I also recommend deleting sitemaps from previous years to improve the frequency of crawling and indexing.
And you, how do you control your indexing? Do you have any new methods for it?
If so, leave it in the comments!


