Estamos en el siglo XXI y si no hablás de machine learning, deep learning, inteligencia artificial, etc. no estás del todo metido en el juego. Este post es una referencia muy básica acerca de qué es el machine learning con ejemplos orientados a SEO.
Cabe aclarar que un tema tan extenso no entra en una nota de blog, así que pueden considerar esto “la punta de la punta del iceberg.” Disclaimer emitido: ¡comencemos!
Primero tenemos que definir bien los términos ya que muchos pueden ser conceptos similares.
Se llama inteligencia artificial a cuando una máquina realiza tareas generalmente delegados a seres humanos. Este término es muy amplio y se recomienda no usarlo ya que no proporciona mucho contexto. Se llama machine learning al concepto de entrenar a una computadora a pensar para que pueda tomar decisiones por su propia cuenta y a construir sobre esos resultados para a su vez aprender a pensar mejor. Deep learning es una técnica de machine learning que se basa en emular el proceso de razonamiento del cerebro humano para encontrar patrones en data no necesariamente catalogada.
Google utiliza machine learning para mejorar sus algoritmos y proporcionar resultados de búsqueda cada vez más relevantes.
El concepto de machine learning no es nuevo sino que se viene usando desde 1959. En los últimos años este término se volvió más popular debido a:
- - El desarrollo de tecnologías que permiten procesar información de manera masiva
- - Una enorme cantidad de data al alcance de todos para ser procesada
Cómo hacer un decision tree para SEO
Una forma de utilizar un decision tree para SEO es generando un checklist de puntos comunes dentro de una auditoría SEO (pagespeed en menos de 3 segundos, validación AMP, presencia de titles, meta description, h1, h2 optimizados, etc.). Para cada uno de los sitios a analizar se debe educar a la máquina con supervised learning.
Qué es el supervised learning o aprendizaje supervisado
El supervised learning es una tarea de machine learning que se basa en educar al algoritmo entre la relación de un input con la del output deseado para que luego pueda categorizar la información de manera no supervisada. Dicho en criollo, le decimos a la computadora “cuando te doy este input, tiene que salir este output” y el algoritmo encuentra la relación entre lo que entra y lo que sale de manera que pueda predecir futuros inputs por su propia cuenta.
Antes de ver un ejemplo de un árbol de decisiones para auditar el SEO de una página web, veamos un par de conceptos más...
Los problemas de
supervised learning se pueden subdividir en dos categorías:
- Clasificación: determinar un output booleano (verdadero o falso, perro o gato, optimizado o no optimizado, etc.)
- Regresión: determinar un output variable real (porcentajes, cantidad de dinero, etc.)
Training data: la información que se le proporciona al algoritmo para entrenarlo
Testing data: la información que se le proporciona al algoritmo para testear su precisión según lo que se le enseñó
Data split: El proceso de separar la data en training y testing para educar y testear al algoritmo
Qué es Train, Test, Split
Se llama train, test, split al proceso de separar la data que se tiene en training y testing. Al terminar el test, se compara el output que devolvió el algoritmo contra el output real que se tenía de ante mano. Si el MAE (error medio absoluto) es bajo, el resultado es bueno y el algoritmo sirv
e para analizar data nueva.

Qué es el MAE o Error Medio Absoluto
Al terminar de procesar un dataset, calculan todos los errores del análisis restando el output correcto del output que devolvió el algoritmo. Luego se hace un promedio de todos los errores y se lo eleva al cuadrado para eliminar los signos negativos (ya que en este caso no interesa si el algo se pasó o quedó corto sino por cuánto falló). El número final es lo que llamamos MAE (mean absolute error) o error medio absoluto. Es una forma de medir si el algoritmo es bueno o no.
Qué se considera un buen resultado de un algoritmo de machine learning
Hace unos años un 85% de precisión se consideraba bueno, pero hoy día con tecnologías más eficientes y algoritmos precisos, el porcentaje se acerca más a un 95%.
Ahora que vimos estos conceptos básicos de machine learning muy por arriba, veamos cómo aplicarlos para SEO.
Cómo hacer un train, test, split
Imaginemos que partimos con un archivo CSV que contiene información del nivel de optimización de ciertos elementos on-site y un puntaje de optimización intuido por un analista SEO experimentado. El archivo puede verse algo así…
Supongamos que este CSV tiene 300 columnas y 1000 filas.* El output que va a tirar el algoritmo es la última columna (puntaje de optimización). Para poder hacer el train, test, split, vamos a tomar un 80% de la data del CSV para educar al algoritmo y el 20% restante para probar si nuestro código es bueno o no. En el 20% que usamos de testing data vamos a despreciar la información de la columna de output y luego que obtengamos el resultado del análisis comparamos lo que dió con lo que debería haber dado.
*Ni Excel ni Google Sheets cuentan con la potencia de manejar archivos tan grandes. Es por esto que se debe usar el módulo Pandas de Python u otro equivalente para procesar la data.
Un ejemplo muy abstracto:
TRAINING INPUT #1:
- Sitio carga en menos de 3 segundos = VERDADERO
- Sitio valida para AMP = VERDADERO
- Presencia de etiquetas SEO optimizadas = VERDADERO
TRAINING OUTPUT #1 PROPORCIONADO AL ALGORITMO:
- Sitio optimizado = VERDADERO
TRAINING INPUT #2:
- Sitio carga en menos de 3 segundos = FALSO
- Sitio valida para AMP = FALSO
- Presencia de etiquetas SEO optimizadas = FALSO
TRAINING OUTPUT #2 PROPORCIONADO AL ALGORITMO:
TESTING INPUT:
- Sitio carga en menos de 3 segundos = VERDADERO
- Sitio valida para AMP = FALSO
- Presencia de etiquetas SEO optimizadas = VERDADERO
TESTING OUTPUT QUE DEVUELVE EL ALGORITMO:
- Sitio optimizado = VERDADERO
Existen varias formas de alcanzar el output. Hablemos de algunas de ellas ya que hasta ahora todo funcionó como por arte de magia.
Decision Trees
Los decision trees (o árboles de decisiones) son mapas con preguntas que, según sus respuestas, van tomando decisiones. Las preguntas podrían ser algo así como…
- “La página está bloqueando al Googlebot con un tag robots noindex, nofollow?” (nodo 1)
- “No.” (rama 1)
- “La página está siendo bloqueada vía robots.txt?” (nodo 2)
- “Sí.” (rama 2)
- “La página no está optimizada para SEO.” (hoja [output])
Se los llaman árboles de decisiones porque partiendo de un tronco (input) cada pregunta es un nodo (ahí se rompe un poco la analogía), cada respuesta es una rama y cada output posible una hoja. A mayor cantidad de nodos, mayor precisión en el output pero mayor el tiempo de procesamiento.
Imagínense un árbol así aplicado para nuestro CSV de ejemplo con cientos de factores a considerar (columnas) y miles de inputs de training data (filas) y se podría alcanzar un resultado medianamente aceptable. Decimos “medianamente aceptables” porque la realidad es que este modelo de machine learning se queda corto para algo tan complejo como analizar si un sitio está optimizado para SEO o no. Se queda corto porque la puntuación para cada uno de esos factores es algo muy subjetivo ya que Google no revela exactamente cuánto pesa cada factor de optimización ni su peso al interactuar con otros factores. Para auditar para SEO a un sitio con machine learning, tendríamos que recurrir a una Neural Net haciendo uso de Deep Learning.
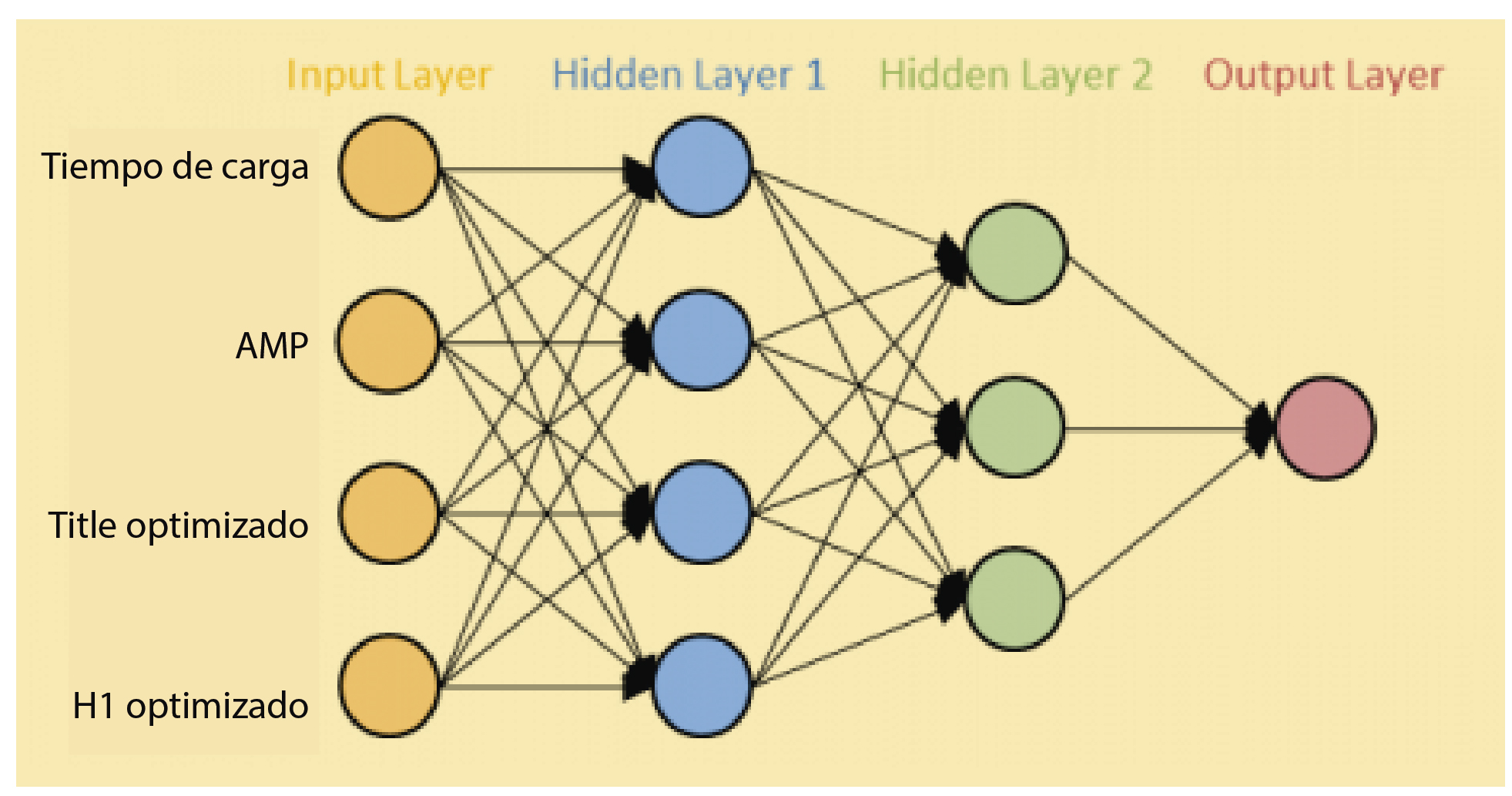
Qué es una Neural Network (Red Neuronal o Neural Net)
En machine learning, una red neuronal es un modelo de entrenamiento recursivo basado sueltamente en la forma en la cual operan las neuronas en los seres vivos. Básicamente, consiste en un layer de inputs, layers ocultos, y un layer de output.
 Cada círculo representa a lo que se llama una neurona (de ahí, red neuronal) y cada línea es un axon. Los axones muestran la conexión entre una neurona y otra.
En un neural net, se le asigna un weight o peso a cada elemento para fluir hacia adelante. El peso se asigna aleatoriamente y es por esto que es más preciso que un modelo de árbol de decisiones. Cómo puede algo aleatorio ser más preciso? Porque elimina la subjetividad: prueba con la mayor cantidad posible de números aleatorios, se fija la desviación del error y ajusta los pesos acorde. Este “ajuste” no sucedía con el decision tree que vimos (aunque hay formas de hacer árboles de decisiones con preguntas variables, pero eso queda fuera del alcance de esta nota).
Cada círculo representa a lo que se llama una neurona (de ahí, red neuronal) y cada línea es un axon. Los axones muestran la conexión entre una neurona y otra.
En un neural net, se le asigna un weight o peso a cada elemento para fluir hacia adelante. El peso se asigna aleatoriamente y es por esto que es más preciso que un modelo de árbol de decisiones. Cómo puede algo aleatorio ser más preciso? Porque elimina la subjetividad: prueba con la mayor cantidad posible de números aleatorios, se fija la desviación del error y ajusta los pesos acorde. Este “ajuste” no sucedía con el decision tree que vimos (aunque hay formas de hacer árboles de decisiones con preguntas variables, pero eso queda fuera del alcance de esta nota).
Qué es una Deep Neural Network
Una deepnet es una red con más de una capa oculta. El ejemplo de la imagen superior cuenta con dos hidden layers así que técnicamente sería una red neuronal profunda. Cualquier red neuronal con más de tres layers (incluyendo las capas de input y output) es considerada una deep neural network. Cada layer hace fluir a los tensores (TensorFlow) haciendo uso de los pesos que mencionamos arriba.
El proceso de asignar pesos aleatorios, medir su resultado, reajustar los pesos y repetir se llama backpropagation (o backprop para la gente más cool).
Cómo puede un algoritmo medir si el output se está acercando o alejando de lo que realmente debería estar dando? Con cálculo lineal! :D
Resulta imposible desarrollar inteligencia artificial sin el uso de la matemática y la estadística. Se hace uso de álgebra porque trabajamos con variables y queremos encontrar valores que no conocemos y usamos cálculo lineal porque tenemos que ver si nos estamos acercando o alejando del error mínimo posible. La estadística nos ayuda a encontrar patrones de comportamiento ya que no siempre se consigue una exactitúd del 100% en un output.
Si tomáramos el CSV de ejemplo con factores de optimización SEO de una página y le asignamos un modelo de red neuronal profundo, se le asignaría un weight aleatorio o peso a cada elemento del input layer y se iría midiendo el resultado del output. Si una deepnet no devuelve el resultado deseado, es probable que se deban agregar más capas ya que la red actual es muy amplia como para dar un resultado preciso. Hay redes muy profundas.
 Para concluir, estos conceptos de machine learning enseñados con un punto de vista orientado a SEO no se consideran para nada exhaustivos sino más bien una introducción de lo que es este mundo llamado inteligencia artificial. Si considerás que querés adentrarte en todo lo relacionado con AI, existe una enorme cantidad de recursos online tanto gratuitos como pagos de los que podés aprender. En PuntoRojo siempre investigamos nuevas formas de mejorar el posicionamiento orgánico de una página en los buscadores y el machine learning no es una excepción. Al hacerlo durante el último año, descubrimos un mundo emocionante lleno de potencial para SEO.
Nos interesa saber si ustedes están complementando sus esfuerzos de optimización web con machine learning. ¡Dejanos tu comentario debajo y que comience el intercambio!
Para concluir, estos conceptos de machine learning enseñados con un punto de vista orientado a SEO no se consideran para nada exhaustivos sino más bien una introducción de lo que es este mundo llamado inteligencia artificial. Si considerás que querés adentrarte en todo lo relacionado con AI, existe una enorme cantidad de recursos online tanto gratuitos como pagos de los que podés aprender. En PuntoRojo siempre investigamos nuevas formas de mejorar el posicionamiento orgánico de una página en los buscadores y el machine learning no es una excepción. Al hacerlo durante el último año, descubrimos un mundo emocionante lleno de potencial para SEO.
Nos interesa saber si ustedes están complementando sus esfuerzos de optimización web con machine learning. ¡Dejanos tu comentario debajo y que comience el intercambio!